
OpenAIが公開した「GPT-5.4 is now available」では、GPT-5.4がChatGPT・API・Codexで提供開始されました。今回の発表は、単なるベンチマーク上の性能向上にとどまらず、業務で使うAIの“実行力”を底上げする内容です。
特に注目すべきは、推論・コーディング・エージェント実行を1つのモデルで強化してきた点です。長文脈を扱う開発、複数ツールを跨ぐ自動化、実務ドキュメント生成まで、現場での「やり切る力」を狙ったアップデートになっています。
まずは公式ベンチマーク比較
| 指標 | GPT-5.4 | GPT-5.3-Codex | GPT-5.2 |
|---|---|---|---|
| GDPval(勝利・引き分けの割合) | 83.0% | 70.9% | 70.9% |
| SWE-Bench Pro(公開版) | 57.7% | 56.8% | 55.6% |
| OSWorld-Verified | 75.0% | 74.0%* | 47.3% |
| Toolathlon | 54.6% | 51.9% | 46.3% |
| BrowseComp | 82.7% | 77.3% | 65.8% |
*以前は64.7%と報告。GPT‑5.3‑Codex は、元の画像解像度を保持する新しいAPIパラメータを使用することで74.0%を達成。
公式比較画像
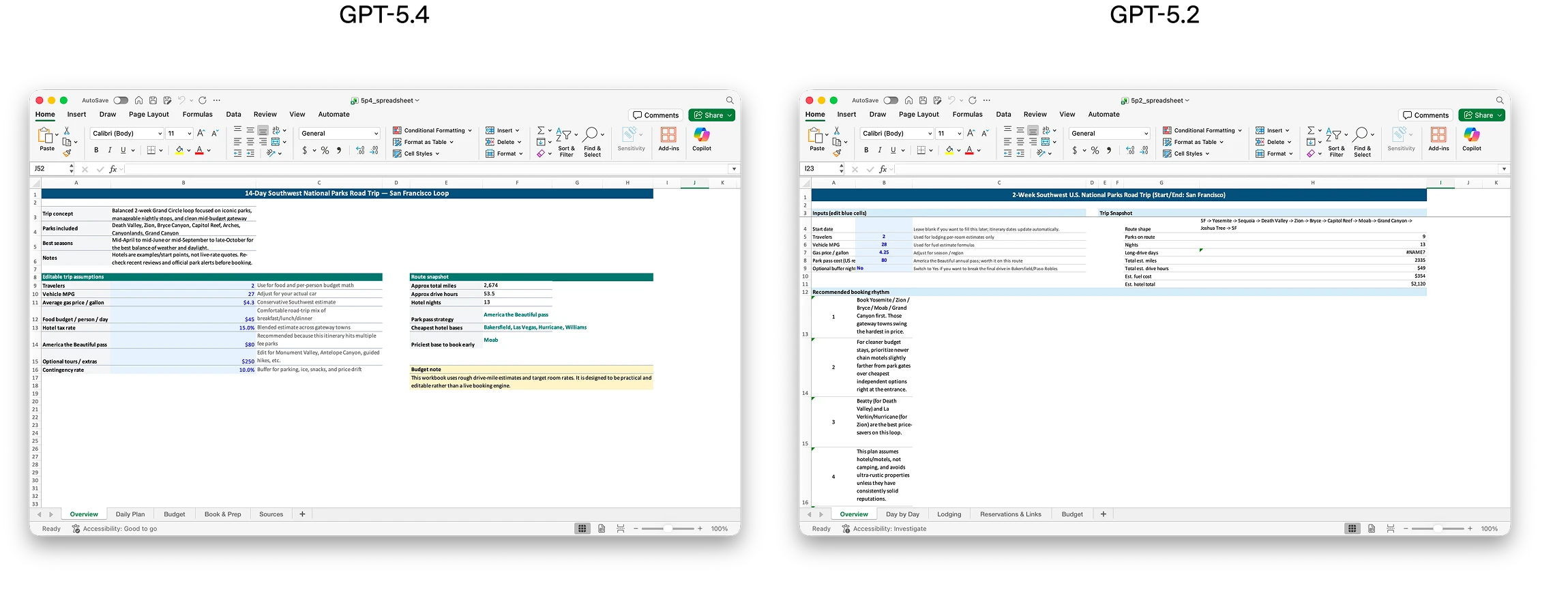
性能向上の中身:どこが“実務向け”なのか
- ネイティブComputer Use:アプリやWebを跨ぐ操作系タスクを想定
- 最大100万トークンのコンテキスト:長い仕様・履歴を保持した推論がしやすい
- tool search:多数ツール環境で必要な定義を必要時に参照しやすい
コーディング面でのメリット
GPT-5.4はGPT-5.3-Codexの強みを取り込みつつ、知識業務・コンピュータ操作まで統合。要件理解→実装→検証まで1モデルで回しやすくなっています。SWE-Bench Proでも57.7%と改善し、反復開発の往復回数削減が期待できます。
また、Computer Use × Coding の相乗効果により、Playwright系のUIテスト自動化や回帰確認まで含めた支援がしやすい点も実務上のメリットです。
ウェブサーチ能力の強化
公式では、ウェブ検索を伴うエージェント型タスクも改善。BrowseCompは82.7%(5.3-Codex: 77.3%、5.2: 65.8%)。単発検索ではなく、反復検索で情報源を絞り込む能力が強化されています。
まとめ
「GPT-5.4 is now available」は、性能向上だけでなく、コーディング・エージェント実装・ウェブ調査を含む実務フローの完遂率を上げるアップデートです。開発と業務自動化を同時に進める現場ほど、検証優先度が高いリリースと言えるでしょう。


コメント