
OllamaのMLX対応が話題になっていたので、手元のMac M1 Max 64GBで、既存の mlx-lm.server 環境と実際に比較してみました。結論から言うと、簡単さではOllama、速度ではmlx-lm.server という、かなり分かりやすい結果になっています。
この記事で見ていくこと
今回の比較では、単なるベンチマーク数字だけではなく、「実際に使うならどちらが快適か」という観点を重視しました。Todoアプリ生成、8ファイル構成のブロック崩しゲーム生成、思考ON/OFF比較まで含めて見ています。

先に結論:乗り換え判断は「速度」より「何を重視するか」
- 速度重視なら mlx-lm.server 継続が有力
- 手軽さ重視なら Ollama MLX はかなり魅力的
- 品質は大差ないが、思考ON時の完成度は mlx-lm.server が一歩上
つまり、今回のMLX対応でOllamaが一気に“使える選択肢”にはなったものの、M1 Max環境ではまだ完全な逆転までは起きていません。
比較条件
| 項目 | mlx-lm.server | Ollama 0.20.2 |
|---|---|---|
| モデル | Qwen3.5-35B-A3B-4bit-fp16 | qwen3.5:35b-a3b-coding-nvfp4 |
| 形式 | safetensors (MLXネイティブ) | GGUF (MLX経由) |
| サイズ | 18GB | 21GB |
| キャッシュ | 15GB明示設定 | 自動管理 |
ここでポイントになるのが、M1/M2系ではbf16がネイティブに強くないこと。手元のmlx-lm.server環境では、bf16→fp16変換済みモデルを使っているため、この差が速度に効いている可能性があります。
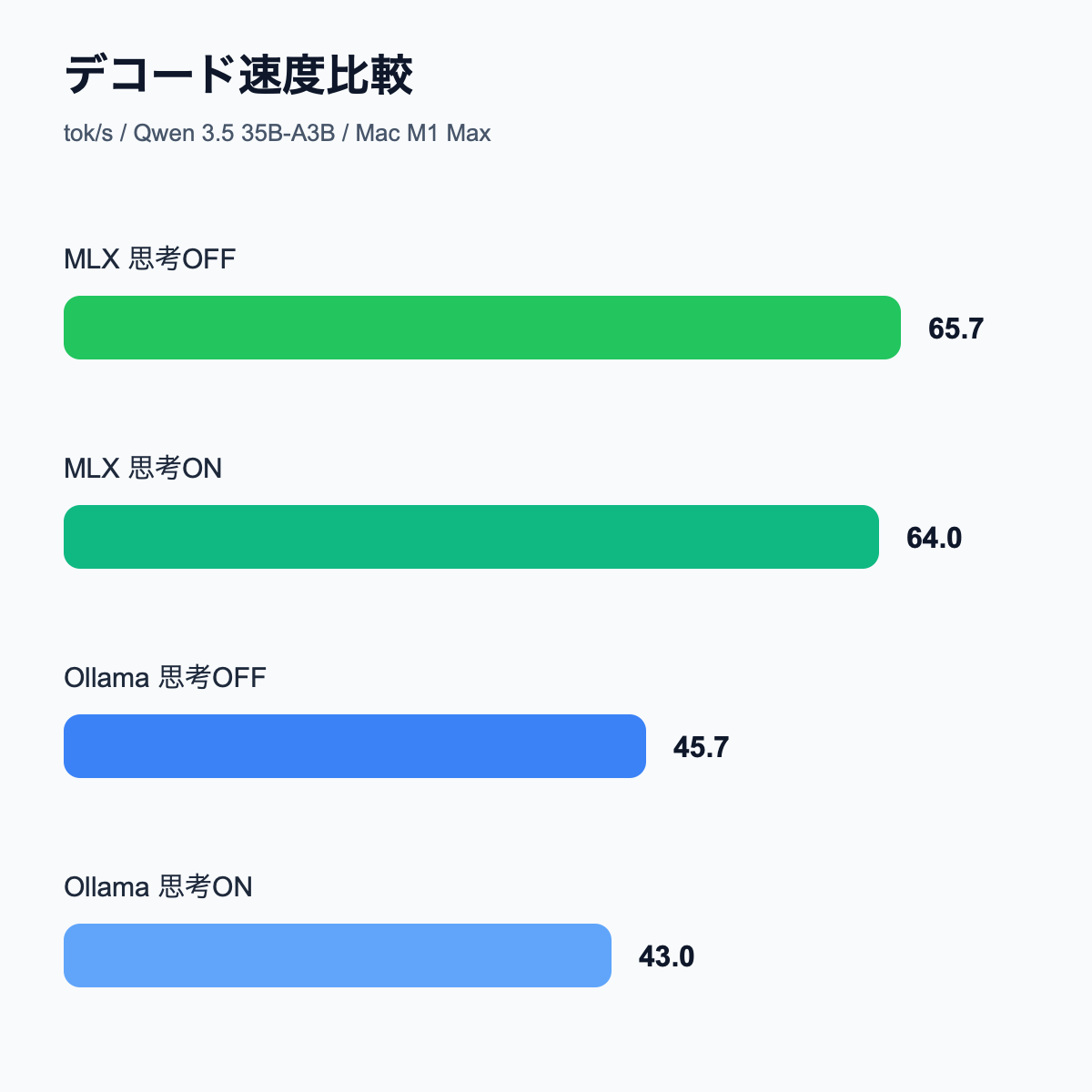
速度比較:MLXネイティブの強さはまだ大きい
Todoアプリ生成では、mlx-lm.serverが最大67.2 tok/s、Ollama NVFP4は45.2 tok/sでした。8ファイル構成のゲーム生成でも、mlx-lm.server 65.7 tok/sに対してOllama 45.7 tok/s。おおむね44〜49%ほど mlx-lm.server が高速です。
この差は、日常の1回1回では「ちょっと速い」程度に見えても、記事下書きやコード生成を繰り返すと体感差になります。特に長めの出力を何本も試す使い方では、無視しにくい差です。
品質比較:同点ではなく「傾向の違い」が出た
面白かったのは、品質そのものは大きく崩れなかったことです。Todoアプリ生成では両者100点。ゲーム生成でも両者95点前後で、基本要件はほぼ達成しています。
ただし出力の“性格”は違いました。
- mlx-lm.server:追加機能を勝手に盛る傾向がある
- Ollama NVFP4:指示への忠実度が高く、無難にまとめる傾向がある
たとえば、mlx-lm.serverはパワーアップ描画やCSS変数など、指示外の工夫を入れてきた一方、軽微なバグも混ざりました。Ollamaは大きく外さない代わりに、遊びや盛りは少なめでした。
思考ONは価値があった。しかも速度低下は軽い
今回かなり印象が良かったのは、mlx-lm.serverで思考ON(temperature 0.6)を使ったケースです。速度は 65.7 tok/s → 64.0 tok/s とほぼ横ばいなのに、品質は95点から100点へ改善。未完成だったボール増加機能が完全実装され、衝突判定もより丁寧になりました。
この結果を見る限り、複雑なコーディング用途では 「思考ON + mlx-lm.server」 の組み合わせが一番バランスが良さそうです。
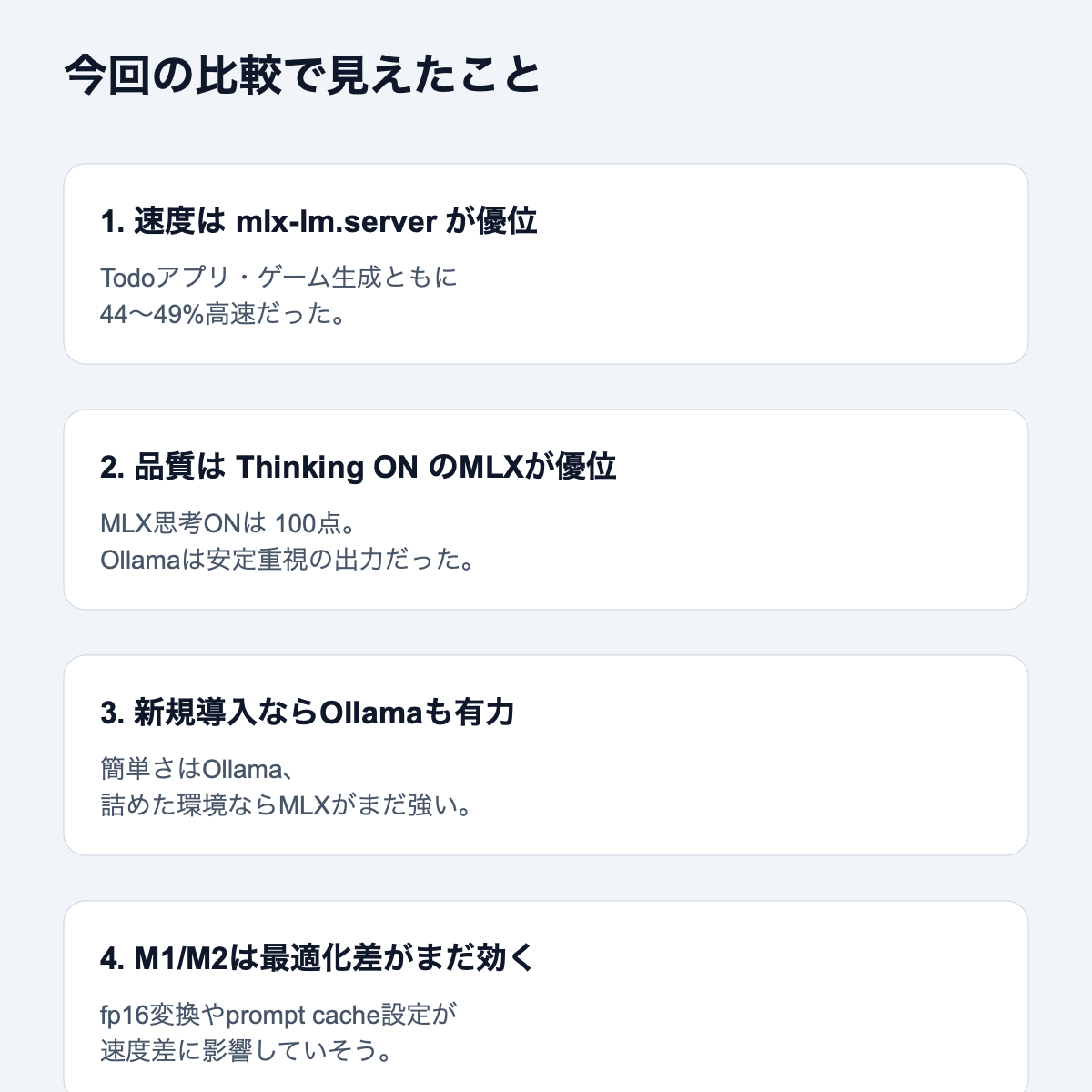
結局どっちを使うべきか
自分の結論はかなりはっきりしています。
- 既にmlx-lm.serverを使っていて、速度重視なら乗り換え不要
- これから始める、あるいは管理の簡単さを重視するならOllama MLXは有力
- M1 Maxクラスでは、まだmlx-lm.serverの優位が大きい
今回のMLX対応でOllamaが「遅いから選べない」存在ではなくなったのは確かです。ただ、すでに最適化済みのmlx-lm.server環境を持っているなら、わざわざ全面移行するほどのメリットは見えませんでした。
この記事のポイントをひと言で言うと
“Ollama MLXはかなり良くなった。でも、本気で詰めたmlx-lm.serverはまだ速い”。これが今回の検証結果です。

コメント